Top 10 Data Engineering Skills Every Company Needs in 2026
Most in demand skills for data engineers in 2026

Most in demand skills for data engineers in 2026
Data Engineering has become one of the most essential disciplines in today’s data-driven world. Whether you’re a student, a beginner exploring tech, techie or someone interested in how companies use…
Data modeling is a structured approach to designing and organizing data for a database or system. Here are the key steps: 1. Identify Business RequirementsUnderstand the purpose of the data…
Following are the most important topics in bigquery. This is also important topics in a perspective of GCP Profession Data Engineer exam.
What Are Accumulators, and How Do They Work? This is a most frequently asked PySpark interview question! Here’s the breakdown: What Are Accumulators? How Do They Work? Example: Pro Tip:…
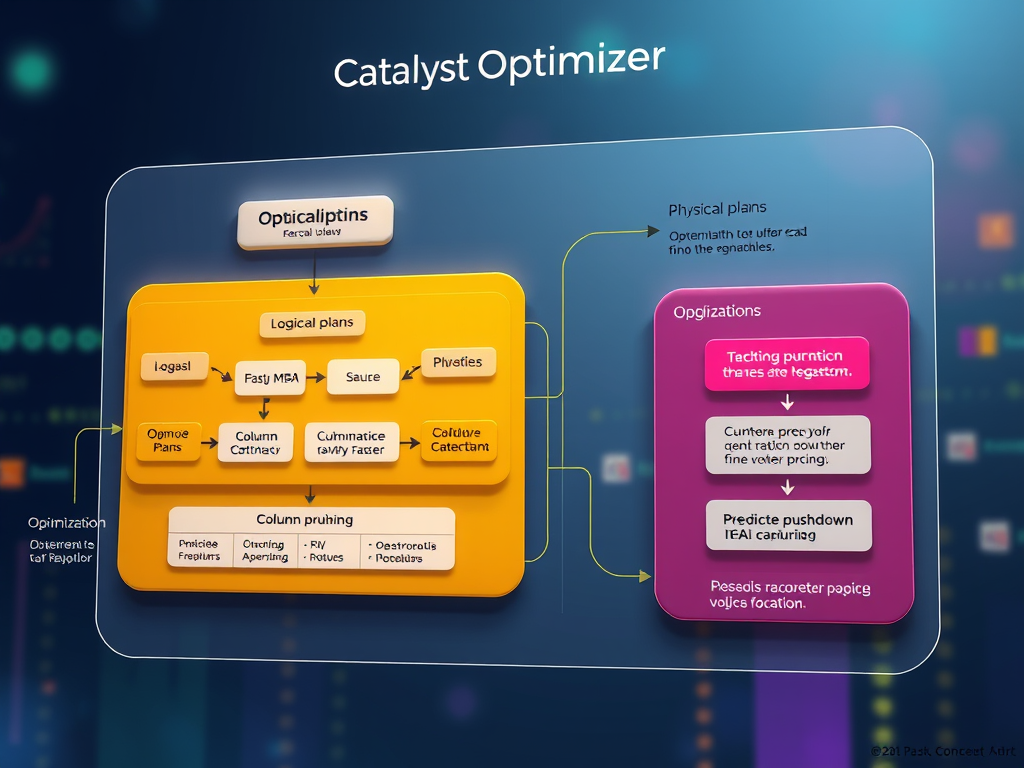
𝗪𝗵𝗮𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗖𝗮𝘁𝗮𝗹𝘆𝘀𝘁 𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿, 𝗮𝗻𝗱 𝗛𝗼𝘄 𝗗𝗼𝗲𝘀 𝗜𝘁 𝗪𝗼𝗿𝗸? This is a must-know PySpark interview question! Here’s the breakdown: 𝗪𝗵𝗮𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗖𝗮𝘁𝗮𝗹𝘆𝘀𝘁 𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿? 𝗛𝗼𝘄 𝗗𝗼𝗲𝘀 𝗜𝘁 𝗪𝗼𝗿𝗸? 𝗞𝗲𝘆…
𝗛𝗼𝘄 𝗗𝗼 𝗬𝗼𝘂 𝗛𝗮𝗻𝗱𝗹𝗲 𝗦𝗸𝗲𝘄𝗲𝗱 𝗗𝗮𝘁𝗮 𝗶𝗻 𝗣𝘆𝗦𝗽𝗮𝗿𝗸? This is a critical PySpark interview question! Here’s the breakdown: ✅ 𝗪𝗵𝗮𝘁 𝗶𝘀 𝗦𝗸𝗲𝘄𝗲𝗱 𝗗𝗮𝘁𝗮? A skewed partition in Spark occurs when…
You have the following code. Explain how the catalyst optimizer works in the code? Explain in detail PySpark’s Catalyst Optimizer is a powerful query optimizer used by Spark SQL to…
if in your code/query if you are filterring the data at the end, Catalyst optimizer (in prediction pushdown) will apply filtering on input or source and then do the other…
both cache() and persist() store data in memory to speed up the retrieval of intermediate data used for computation. However, persist() is more flexible and allows users to specify storage…